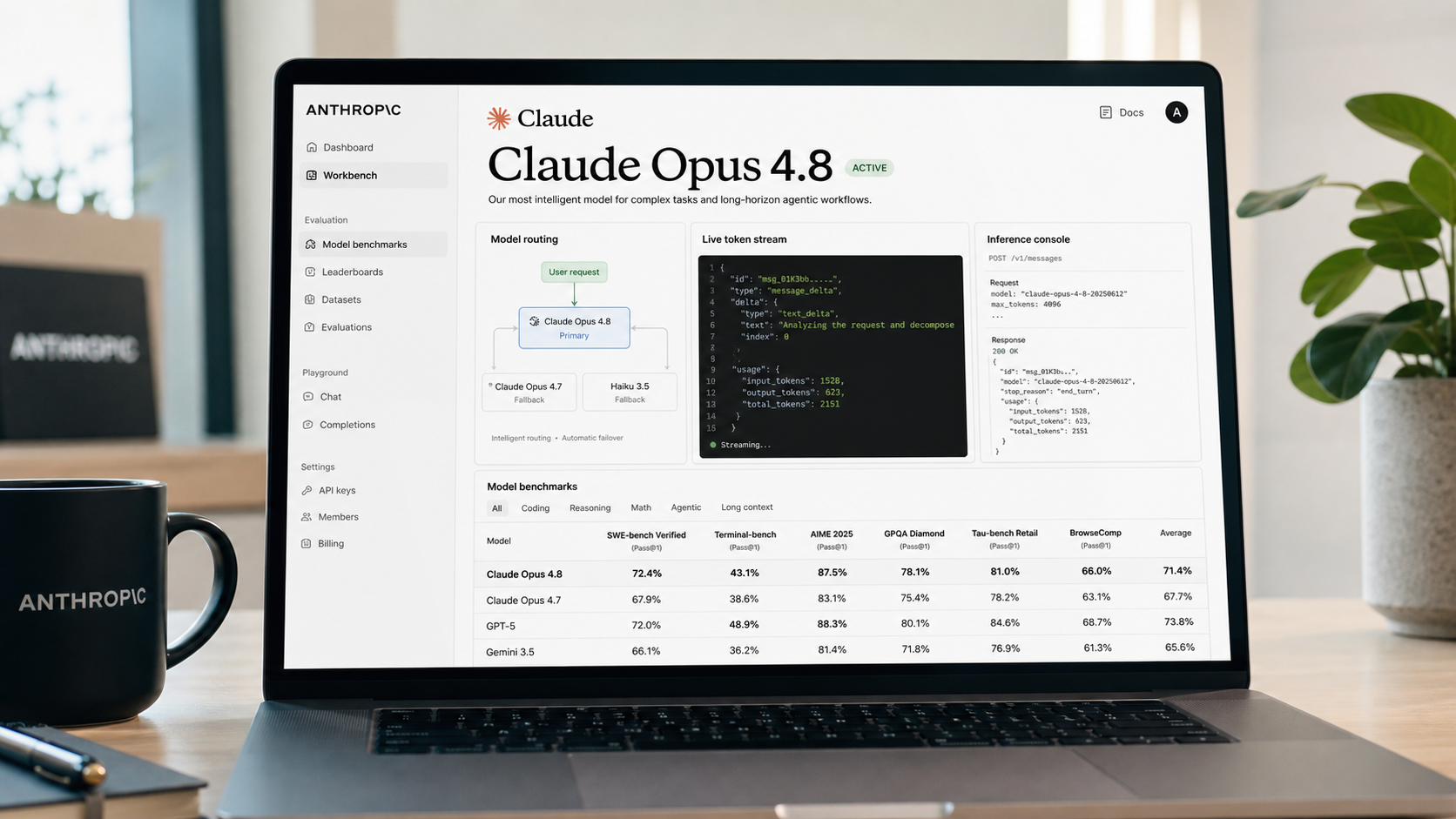
Claude Opus 4.8 API documentation.
How does Opus 4.8 compare to GPT-5.5 on coding and agentic benchmarks?
Claude Opus 4.8 leads GPT-5.5 on every published benchmark where both scores are available. On SWE-Bench Pro (agentic coding), Opus 4.8 scores 69.2% vs. GPT-5.5's 58.6% — a 10.6-point gap. On GDPval (knowledge work and economic tasks), Opus 4.8 scores 1,890 vs. GPT-5.5's 1,769 . On Online-Mind2Web (computer use), Opus 4.8 scores 84% and Anthropic describes its lead over GPT-5.5 as "meaningful" — GPT-5.5's exact score is not disclosed in current release materials. Opus 4.8 is also the only model to complete every case end-to-end in Anthropic's Super-Agent evaluation; GPT-5.5 does not. All figures are from Anthropic's internal benchmarks unless otherwise noted; independent third-party verification was not available at time of publication.
What to Watch: Mythos Availability, Fast Mode GA, and Dynamic Workflows
Opus 4.8 is a substantive step forward from Opus 4.7 for developers building agentic systems. The SWE-Bench Pro improvement from 64.3% to 69.2% is the sharpest single-release gain in the Opus 4.x series. The three stable API additions — mid-conversation system messages, refusal stop details, lower cache minimum — address specific developer friction without requiring architectural rewrites. And Fast Mode pricing at $10/$50 makes latency-sensitive Claude deployments more accessible than they were under prior fast-mode tiers.
Two near-term items warrant monitoring before committing to production. Fast Mode carries a research preview label: throughput guarantees are provisional, and behavior under sustained load may differ from the stated 2.5× ceiling. Test it against your actual latency profile and traffic mix before wiring it to a production SLA. Dynamic Workflows in Claude Code opens genuinely new surface area for large-scale parallel subagent orchestration, but the coordination mechanics at hundreds-of-agents scale are not yet fully documented — expect the API contract to tighten as the preview matures toward general availability.
Mythos-class models remain the unknown variable for any team planning a model roadmap beyond Q2 2026. Anthropic has not released benchmark data or specific capability claims for Mythos publicly. Given that Opus 4.8 is already the only model to complete all Super-Agent cases end-to-end, the capability delta between Mythos and Opus 4.8 is not predictable from current information. Until Mythos specs are public, Opus 4.8 at $5/$25 standard pricing is the practical production choice for most agentic workloads — with Fast Mode as an opt-in for paths where latency justifies the 2× cost premium.
Last updated: 2026-05-29. Based on Anthropic's May 28, 2026 release announcement, the official Claude Opus 4.8 product page, and the Anthropic API documentation. Benchmark figures are as reported by Anthropic; independent third-party verification was not available at time of publication.