Claude Opus 4.8 API 문서.
Opus 4.8은 코딩 및 에이전틱 벤치마크에서 GPT-5.5와 어떻게 비교되나요?
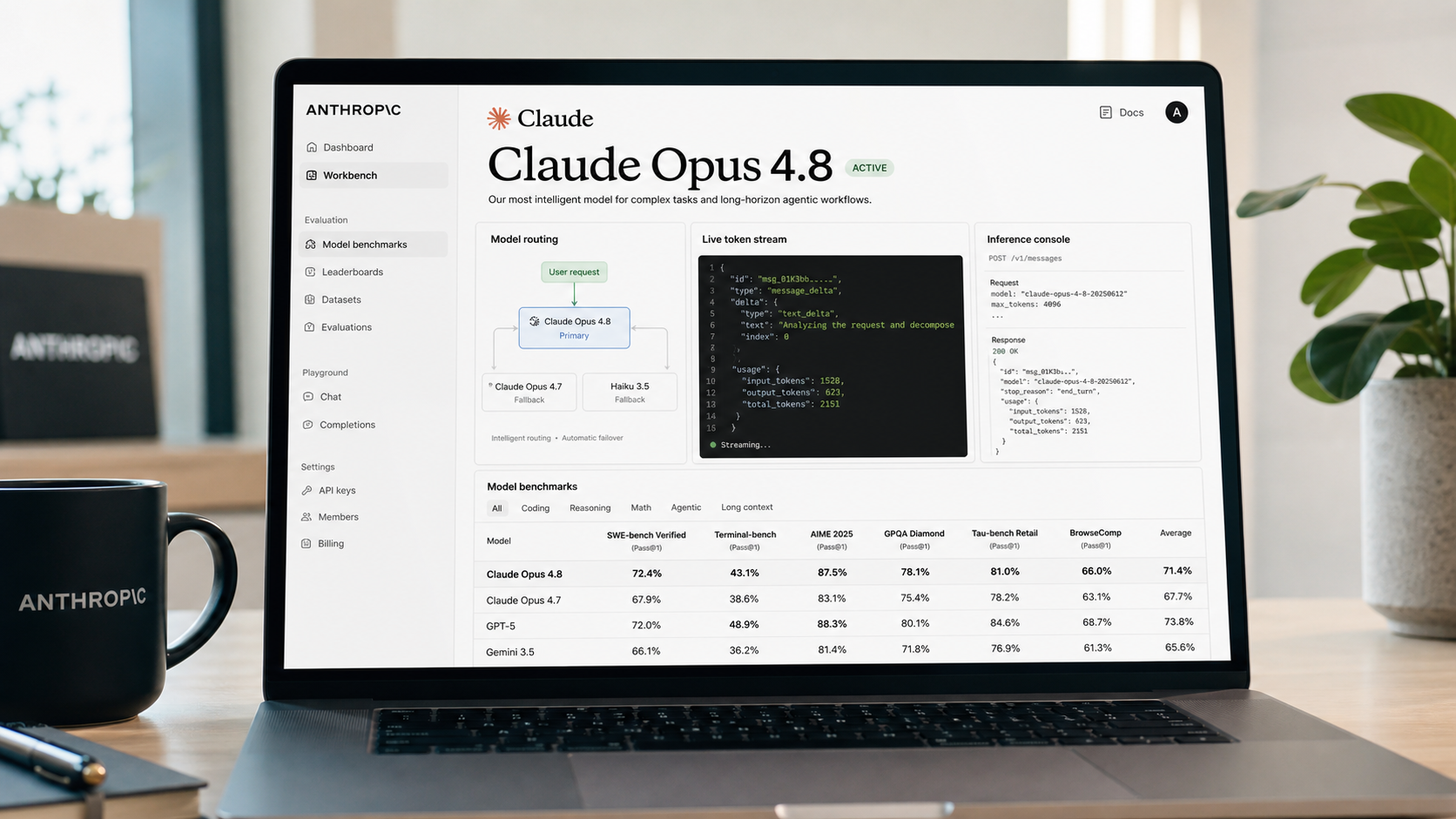
Claude Opus 4.8은 양측 점수가 공개된 모든 벤치마크에서 GPT-5.5를 앞섰다. SWE-Bench Pro(에이전틱 코딩)에서 Opus 4.8은 69.2%를 기록했고, GPT-5.5는 58.6%에 그쳤다 — 10.6포인트 차이다. GDPval(지식 업무 및 경제 과제)에서는 Opus 4.8이 1,890점, GPT-5.5가 1,769점을 기록했다 . Online-Mind2Web(컴퓨터 사용)에서 Opus 4.8은 84%를 기록했으며, Anthropic은 GPT-5.5 대비 우위를 "의미 있는" 수준이라고 표현했다 — GPT-5.5의 정확한 점수는 현재 릴리스 자료에 공개되지 않았다. 또한 Opus 4.8은 Anthropic의 Super-Agent 평가에서 모든 케이스를 처음부터 끝까지 완료한 유일한 모델이며, GPT-5.5는 그렇지 못했다. 별도 언급이 없는 한 모든 수치는 Anthropic 내부 벤치마크 기준이며, 발행 시점에 독립적인 제3자 검증은 이루어지지 않았다.
주목해야 할 사항: Mythos 가용성, Fast Mode GA, 그리고 Dynamic Workflows
Opus 4.8은 에이전틱 시스템을 구축하는 개발자에게 Opus 4.7에서 실질적으로 한 단계 도약한 모델이다. SWE-Bench Pro 점수가 64.3%에서 69.2%로 향상된 것은 Opus 4.x 시리즈 전체를 통틀어 단일 릴리스 기준 가장 큰 상승폭이다. 세 가지 안정적인 API 추가 기능 — 대화 중 시스템 메시지, 거부 중단 세부 정보, 낮아진 캐시 최솟값 — 은 아키텍처 재설계 없이도 개발자의 구체적인 불편 사항을 해소해 준다. 그리고 Fast Mode 가격($10/$50)은 이전 고속 모드 티어 대비 지연 시간에 민감한 Claude 배포를 한층 쉽게 접근할 수 있게 만든다.
프로덕션 도입을 결정하기 전에 모니터링이 필요한 두 가지 단기 항목이 있다. Fast Mode는 리서치 프리뷰 레이블을 달고 있어, 처리량 보장은 잠정적이며 지속적인 부하 상황에서의 동작이 명시된 2.5× 상한과 다를 수 있다. 프로덕션 SLA에 연결하기 전에 실제 지연 시간 프로파일과 트래픽 조합에 맞게 충분히 테스트해야 한다. Claude Code의 Dynamic Workflows는 대규모 병렬 서브에이전트 오케스트레이션을 위한 새로운 가능성을 열어 주지만, 수백 개 에이전트 규모에서의 조율 메커니즘은 아직 완전히 문서화되지 않았다 — 프리뷰가 정식 출시로 성숙해 가면서 API 계약이 구체화될 것으로 예상된다.
Mythos 클래스 모델은 2026년 2분기 이후의 모델 로드맵을 계획하는 모든 팀에게 미지의 변수로 남아 있다. Anthropic은 Mythos에 대한 벤치마크 데이터나 구체적인 기능 주장을 공개하지 않았다. Opus 4.8이 이미 모든 Super-Agent 케이스를 처음부터 끝까지 완료한 유일한 모델인 만큼, Mythos와 Opus 4.8 간의 성능 차이는 현재 정보로는 예측하기 어렵다. Mythos 사양이 공개되기 전까지, 표준 가격 $5/$25의 Opus 4.8이 대부분의 에이전틱 워크로드에 현실적인 프로덕션 선택지다 — 지연 시간이 2× 비용 프리미엄을 정당화하는 경로에는 Fast Mode를 선택적으로 활용할 수 있다.
최종 업데이트: 2026-05-29. Anthropic의 2026년 5월 28일 릴리스 발표, 공식 Claude Opus 4.8 제품 페이지, Anthropic API 문서를 기반으로 작성되었습니다. 벤치마크 수치는 Anthropic이 보고한 내용이며, 발행 시점에 독립적인 제3자 검증은 이루어지지 않았습니다.

