Phase 2, released January 27, 2026 , added custom subagents for parallel specialized tasks, multi-choice clarification prompts to reduce unintended edits, slash-command skills mapping single commands to predefined workflows, and continuous automatic CLI updates. Access was tied to Le Chat subscription tiers, with a free Experiment tier enabling limited evaluation.
Phase 3 arrived May 22, 2026 , alongside Mistral Medium 3.5 — a 128B dense model scoring 77.6% on SWE-bench Verified under a modified MIT license . Remote agents now run coding sessions in isolated cloud sandboxes without requiring the developer's machine to stay online. By May 2026, the CLI repository had accumulated 4,300 stars and 509 forks on GitHub .
This comparison covers architecture, benchmark numbers, pricing, multi-agent and MCP integration, data residency, and a decision framework for teams currently evaluating Vibe against Copilot and Cursor.
Architecture: Terminal CLI vs IDE Plugin vs Remote Sandbox
The three tools occupy structurally different positions in the developer workflow stack. GitHub Copilot is IDE-embedded: inline completion and a chat sidebar are the primary interface, with Copilot Workspace providing task-level orchestration scoped to GitHub repositories. Cursor is a VS Code fork with deep codebase indexing and a persistent large-context chat panel built into the editor. Mistral Vibe is terminal-native — the agent operates through a CLI, not an editor sidebar — with optional async offload to isolated cloud sandboxes for long-running or compute-intensive sessions. Architecture determines which workflows each tool can serve natively, and where integration friction appears.
Copilot's compute runs on GitHub infrastructure with no local requirement. Copilot Workspace handles multi-step task planning within GitHub but requires an active connection and an IDE or browser session. For teams already embedded in GitHub, VS Code, or JetBrains, this is low-friction. For teams automating coding tasks in CI pipelines or working primarily in the terminal, Copilot's architecture adds overhead at the integration layer.
Cursor's VS Code fork adds deep codebase indexing — semantic search across large repos — and a persistent chat pane maintaining multi-turn context. Model selection (GPT-4o, Claude 3.7 Sonnet, Gemini) happens in settings and switching is low-friction. Cursor's terminal integration exists but is secondary; the workflow is fundamentally editor-centric. MCP support is available, but async remote execution is not part of the product's architecture.
Vibe's Phase 3 remote agents introduced the most architecturally distinct capability in this comparison. Sessions run in isolated cloud sandboxes — multiple in parallel — without requiring the developer's local environment to stay active . The "Teleport" feature migrates an active local CLI session to a cloud sandbox, preserving full task history, approval context, and in-progress tool calls. After teleportation, the developer's machine can go offline; the session continues executing. This is a full session migration with state preservation, not a background polling daemon.
Approval gates are built into Vibe's execution model. On destructive operations or ambiguous multi-step edits, the agent pauses and surfaces a question inline, which the developer can respond to asynchronously. Live file diffs and tool-call logs are visible mid-session, making oversight auditable without constant monitoring. For teams with code review requirements or security-sensitive deployment workflows, this property has practical value beyond convenience.
Built-in agent profiles — default, plan, accept-edits, auto-approve, and lean — cover the spectrum from high human oversight to largely autonomous operation. Project-level configuration at ./.vibe/config.toml overrides user-level settings at ~/.vibe/config.toml, enabling per-repository behavior tuning without modifying global settings.
The practical tradeoff: developers whose primary environment is an IDE and who rarely leave the editor will find Copilot or Cursor lower-friction. Teams that automate coding tasks in CI pipelines, prefer terminal-first toolchains, or need async remote execution have architecture-level reasons to evaluate Vibe — the difference is capability, not preference.
Benchmark Numbers: SWE-bench Verified Scores in Context
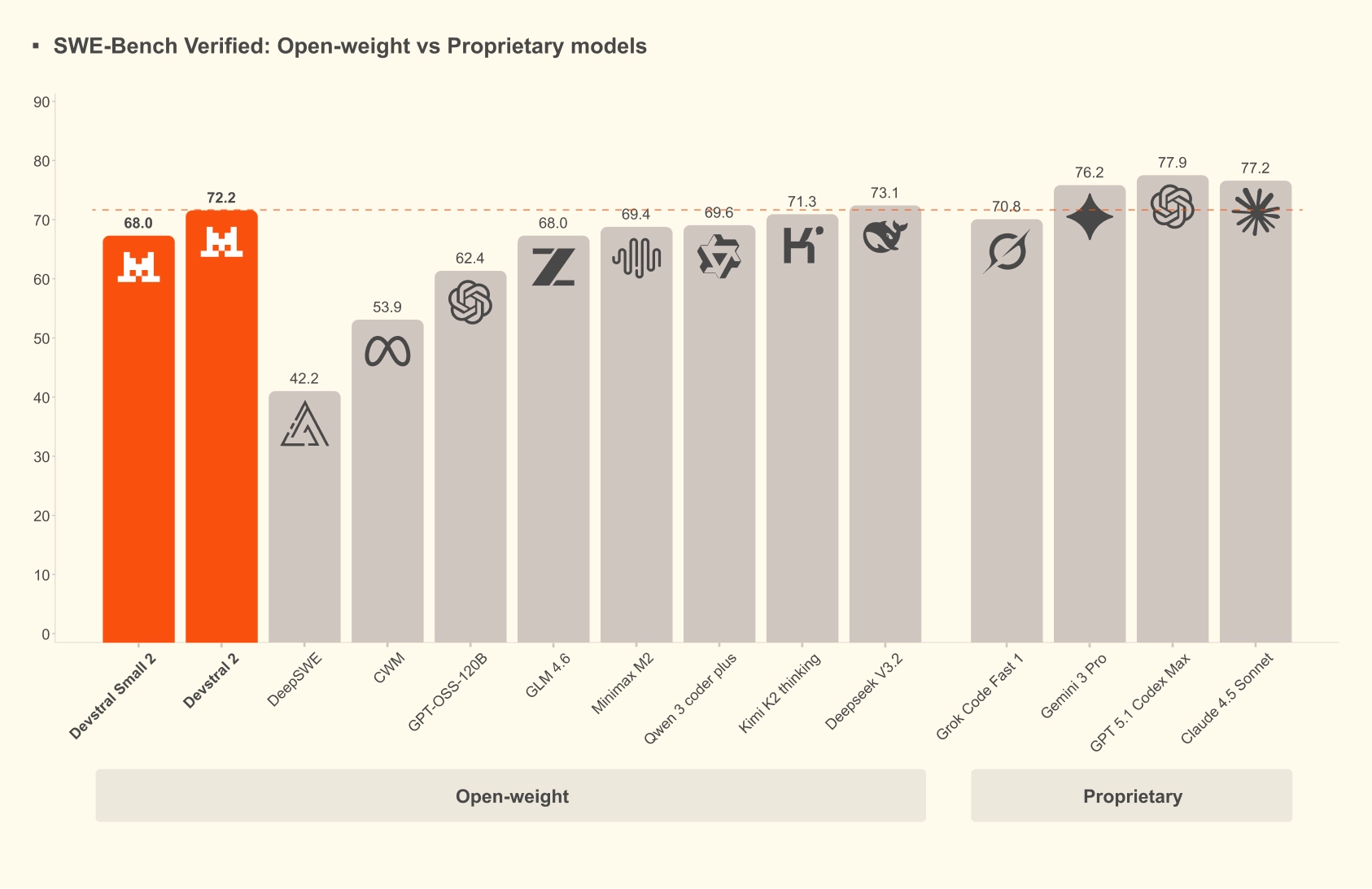
SWE-bench Verified tests models against real GitHub issues requiring multi-file edits — not autocomplete accuracy or single-file generation. Each task requires understanding a repository's structure, identifying the relevant files, and producing a patch that passes the issue's test suite. It is a better proxy for agentic development work than completion benchmarks, though still limited: production codebase complexity, legacy code patterns, and organizational workflow integration fall outside what the benchmark measures. Use these scores to establish a baseline, not to make a final tooling call.
Mistral's three models span a meaningful range. Mistral Medium 3.5 scores 77.6% on SWE-bench Verified and 91.4 on τ³-Telecom , outperforming both Devstral 2 at 72.2% and Qwen3.5 397B A17B — a model more than three times larger by parameter count. According to MarkTechPost's coverage, the score positions Medium 3.5 among a small group of models exceeding 75% on this benchmark at comparable inference costs.
| Model | Parameters | SWE-bench Verified | Context Window | License | Min. Hardware (self-host) |
|---|---|---|---|---|---|
| Mistral Medium 3.5 | 128B dense | 77.6% | 256K tokens | Modified MIT | 4× GPUs |
| Devstral 2 | 123B | 72.2% | 256K tokens | Apache 2.0 | Multi-GPU |
| Devstral Small 2 | 24B | 68.0% | 256K tokens | Apache 2.0 | Consumer hardware |
Scores from Mistral's May 2026 announcement and December 2025 launch post. Copilot and Cursor support multi-model selection (GPT-4o, Claude 3.7 Sonnet, Gemini) — no single SWE-bench score applies to either tool; the active backend per session determines effective performance.
"Mistral Medium 3.5 achieves 77.6% on SWE-bench Verified, outperforming much larger open-weight models, while remaining self-hostable at the four-GPU tier — a density and capability combination that has not previously been available at this model size and price point." — Mistral AI, Medium 3.5 and Vibe Remote Agents Release, May 2026
Mistral also claims Devstral 2 is 5x smaller than DeepSeek V3.2 at comparable coding output , and delivers up to 7x cost-efficiency versus Claude Sonnet at real-world tasks . Both figures are self-reported and have not been independently verified at time of writing. Treat them as directional context rather than engineering specifications when modeling costs.
For teams evaluating which Mistral model to use with Vibe, the practical split is straightforward: Devstral Small 2 for cost-sensitive or local inference scenarios; Devstral 2 for the main agent workload at API rates; Medium 3.5 for the highest-fidelity agentic tasks where output quality justifies the higher token cost. All three share the same 256K context window, covering large repository contexts without chunking strategies.
Pricing: Token Costs vs Flat Subscriptions
Mistral Vibe's pricing is token-based, billed through the Mistral API or covered by a Le Chat Pro plan's included quota with pay-as-you-go overage. GitHub Copilot Pro and Cursor Pro are flat monthly subscriptions with usage limits. The right choice depends almost entirely on task volume and session output-token density — not on which headline number is lower. Token-based pricing is cheaper at low or bursty usage; flat subscriptions become more economical at high-volume steady daily use. At CI/CD scale, the economics shift again depending on which model tier is in use.
| Tool / Plan | Model | Input (per M tokens) | Output (per M tokens) | Billing Model |
|---|---|---|---|---|
| Vibe — Devstral Small 2 | 24B | $0.10 | $0.30 | Pay-as-you-go |
| Vibe — Devstral 2 | 123B | $0.40 | $2.00 | Pay-as-you-go |
| Vibe — Medium 3.5 | 128B dense | $1.50 | $7.50 | Pay-as-you-go |
| GitHub Copilot Pro | Multi-model (GPT-4o, Claude, Gemini) | $10 / month flat | Subscription (capped) | |
| Cursor Pro | Multi-model (GPT-4o, Claude, Gemini) | $20 / month flat | Subscription | |
Devstral pricing as of December 2025 ; Medium 3.5 pricing as of May 2026 . Copilot Pro: $10/month [GitHub]. Cursor Pro: $20/month [Cursor]. All figures subject to change.
For individual developers running occasional agent sessions, Copilot Pro's flat $10/month is almost certainly cheaper than token-based Vibe usage. At Devstral 2 output pricing ($2.00/M tokens), a developer would need to generate 5M output tokens before the token model surpasses the flat rate. For casual daily use, that threshold is rarely reached. The crossover changes once you factor in the output-to-input ratio typical of agentic tasks — multi-file edits and PR generation tend to produce 3–5× more output tokens than input tokens, which compounds the effective per-task cost.
The calculation shifts sharply at CI/CD scale. A pipeline running 50 agent tasks per day, each generating 10K output tokens, accumulates roughly 15M output tokens per month. At Devstral 2 rates ($2.00/M output), that costs $30/month — still modest. At Medium 3.5 rates ($7.50/M output), the same volume reaches $112.50/month per pipeline. At that point, Devstral Small 2 at $0.30/M output warrants evaluation against the quality tradeoff, or the economics of self-hosting a 24B model on existing GPU infrastructure become concrete.
The Mistral Vibe product page describes Free, Pro, Team, and Enterprise tiers, with Enterprise pricing not publicly listed . Le Chat Team adds shared workspaces and unified billing. Enterprise adds on-premises deployment and custom fine-tuning. Teams should model their expected output-token volume per task type before relying on Mistral's self-reported efficiency figures — the math is task-shape-dependent.
Multi-Agent and MCP Integration

Vibe's multi-agent architecture is native rather than an add-on. Custom subagents — introduced in Vibe 2.0 on January 27, 2026 — run as specialized sub-processes alongside the primary agent session. A typical configuration might run a PR review subagent, a test-generation subagent, and a deploy-script subagent concurrently. This parallel execution model reduces the synchronous bottleneck where tasks queue behind a single agent thread — meaningful for any workflow where several distinct coding concerns need to be addressed in the same session.
MCP server integration is built into the CLI without custom glue code. External tools, APIs, and databases connect through the Model Context Protocol, with configuration living in the project's .vibe/config.toml. MCP server connections defined in that file are version-controllable and shareable across the team — the integration definition ships with the code, not as undocumented per-machine configuration. According to the Vibe 2.0 launch announcement, MCP integration treats connected tools as first-class context sources rather than external call-outs requiring a round-trip at query time.
"With MCP server support built in natively, Vibe connects to your existing tools, APIs, and databases as first-class context — no integration wrapper, no custom glue code required." — Mistral AI, Vibe 2.0 Release Announcement, January 2026
Slash-command skills extend the automation surface further. A team defines /deploy, /lint, or /document in the project config file; Vibe executes the corresponding multi-step workflow with a single command entry. These definitions are version-controlled, shareable, and auditable — a meaningful property for teams that need reproducible agent behavior across developers and CI environments. Slash commands reduce the overhead of re-specifying complex tasks each session without requiring hardcoded scripts outside the agent context.
Phase 3 expanded the integration surface to GitHub (code and pull requests), Linear and Jira (issue tracking), Sentry (incident response), and Slack or Microsoft Teams for session notifications . These connectors position Vibe as part of the broader engineering workflow stack. An issue flagged in Sentry can trigger a Vibe agent session that runs asynchronously, generates a PR, and posts a Slack notification — without a developer initiating each step manually.
Cursor has MCP support, but async remote execution is not native to its architecture. For VS Code-centric teams that need MCP-connected tools for synchronous workflows, Cursor's implementation is adequate. Copilot's Extensions ecosystem is expanding, but MCP adoption within that ecosystem is still early as of May 2026. For teams with complex multi-tool workflows requiring native MCP composition and parallel subagent execution, Vibe's current integration surface is more complete than either alternative.
Data Residency and Self-Host Options
Mistral AI is headquartered in Paris, and EU data residency is structural to its product architecture — not an enterprise add-on applied atop US-based infrastructure. GDPR compliance is the default for API customers. For regulated industries, financial institutions, or organizations operating under data localization requirements, this changes the evaluation framework significantly. Copilot and Cursor both default to US cloud infrastructure; enterprise plans offer regional data agreements, but neither provides model weights for self-hosting.
"Mistral's European origin and enterprise-grade data residency are key differentiators as organizations assess alternatives to US-based AI tooling for code generation." — VentureBeat, coverage of Vibe 2.0 launch, January 2026
On the self-hosting side, hardware requirements split clearly by model tier. Devstral Small 2 at 24B parameters runs on consumer hardware — a well-configured workstation or a single high-memory GPU server . Devstral 2 at 123B requires a multi-GPU setup; Mistral specifies a minimum of four GPUs for Medium 3.5 at 128B dense . Weights are available on Hugging Face and via NVIDIA NIM container inference, lowering the barrier to standardized deployment on existing infrastructure.
License terms are permissive for commercial use. Devstral 2 and Devstral Small 2 carry Apache 2.0 licenses; Medium 3.5 uses a modified MIT license . Both permit commercial self-hosting without per-seat royalties or vendor lock-in beyond infrastructure cost. One caveat worth tracking: the specific terms of Medium 3.5's "modified MIT" license have not been publicly detailed as of May 2026. Teams planning commercial self-hosting at scale should review the actual license text before committing to that deployment path.
For air-gapped environments or strict on-premises policy, Vibe with self-hosted Devstral is the only path among these three tools supporting full on-premises deployment. Copilot Business and Enterprise offer regional data controls and data agreements but no self-hosting option — weights are proprietary. Cursor's Enterprise tier similarly provides data agreements without a self-hosting path. For defense contractors, healthcare organizations, or financial institutions where data cannot leave specific infrastructure, Copilot and Cursor are effectively ruled out by architecture, regardless of their other capabilities. Mistral's stated positioning — "intelligence you own, not rent" — reflects this structural difference rather than just marketing framing.
Decision Framework: Which Tool Fits Which Team

Benchmark scores and feature lists tend to compress meaningful differences into superficial rankings. The decision between Vibe, Copilot, and Cursor is more usefully framed around workflow architecture, team context, and hard constraints — particularly when one dimension (data residency, CI/CD integration, or cost at scale) is non-negotiable.
Choose GitHub Copilot if:
- Your team is already embedded in GitHub and primarily uses VS Code, JetBrains, or another Copilot-supported IDE.
- Inline completions and an IDE chat sidebar cover the majority of the coding workflow.
- Multi-model switching (GPT-4o, Claude 3.7 Sonnet, Gemini) within the same tool is a priority without changing environments.
- Copilot Workspace's task-level orchestration within GitHub repositories is sufficient for your agentic needs.
- Flat pricing at $10/month [GitHub] is more predictable than token-based billing for your usage pattern.
Choose Cursor if:
- Your team prefers a VS Code-compatible environment with deep codebase indexing and a polished multi-turn chat interface.
- Terminal dependency is minimal — the primary workflow is editor-centric.
- You want multi-model flexibility within a single fork rather than switching between tools.
- $20/month flat [Cursor] is acceptable and usage volume is high enough to favor predictable pricing over per-token billing.
- MCP integration matters but async remote execution is not a workflow requirement.
Choose Mistral Vibe (API / Le Chat Pro) if:
- Your workflow is terminal-first or CI/CD-centric rather than editor-centric.
- EU data residency or GDPR compliance is a structural requirement, not a preference.
- Async remote task execution — running agent sessions without keeping a local machine awake — adds operational value.
- You need native MCP integration and parallel subagent execution without additional tooling overhead.
- Token-based pricing fits better because usage is bursty or project-specific rather than steady-state daily use.
Choose Vibe + self-hosted Devstral if:
- Your environment is air-gapped or subject to strict on-premises data policy.
- Token costs at CI/CD scale — hundreds of agent runs per day — make SaaS API pricing untenable.
- You have GPU infrastructure to run 24B (Devstral Small 2, consumer hardware) or 123B+ (Devstral 2 / Medium 3.5, minimum four GPUs) models .
- Custom fine-tuning on internal languages or legacy codebases is on the roadmap via the Enterprise tier .
One consideration worth stating directly: Copilot and Cursor both allow backend selection from current frontier models, which means their effective quality ceiling is not fixed — it moves with whatever GPT-4o, Claude, or Gemini releases. Vibe's ceiling is currently Medium 3.5 at 77.6% SWE-bench Verified — competitive but not unconditionally above all alternatives for all task types. For teams where raw model quality is the primary criterion and tooling flexibility is secondary, the multi-model approach in Copilot or Cursor may deliver a higher effective ceiling per session through active model selection.
Frequently Asked Questions
Is Mistral Vibe free to use?
Mistral Vibe has a free Experiment tier offering limited evaluation access. Full usage requires either a Le Chat Pro subscription or direct API access with pay-as-you-go billing . The CLI itself is MIT-licensed and open-source — there is no charge for the software. What you pay for is model inference: billed per token through the Mistral API, or drawn from a Le Chat Pro plan's included quota, with overage billed at API rates above the limit. There are no ongoing software license fees for the CLI.
How do Devstral 2 and Medium 3.5 SWE-bench scores compare to what Copilot and Cursor use?
Mistral Medium 3.5 scores 77.6% on SWE-bench Verified, and Devstral 2 scores 72.2% . GitHub Copilot and Cursor are multi-model platforms — users can select GPT-4o, Claude 3.7 Sonnet, or Gemini as the active backend, each with a different SWE-bench profile. No single score represents Copilot or Cursor's performance; the active model selection per session determines effective capability. The Mistral scores are competitive at the Devstral 2 tier and strong at Medium 3.5, but do not set an absolute ceiling relative to all frontier models available through those platforms.
Can Mistral Vibe run fully on-premise?
Partially. The CLI is open-source and operates against a self-hosted model inference backend. Devstral Small 2 (24B parameters) runs on consumer hardware ; Devstral 2 (123B) and Medium 3.5 (128B, minimum four GPUs) require multi-GPU infrastructure . Both model families carry permissive licenses (Apache 2.0 and modified MIT) allowing commercial self-hosting. The exception: Phase 3 remote agent features — async cloud sandboxes and Teleport session migration — require Mistral cloud infrastructure and cannot be self-hosted. Teams in fully air-gapped environments can run local CLI sessions against local inference, but lose the remote execution capabilities introduced in Phase 3.
Which IDEs does Mistral Vibe support?
Vibe is terminal-native rather than IDE-embedded. Official integrations at launch included a Zed IDE extension, Kilo Code, and Cline . There is no native VS Code plugin as of May 2026. Teams with VS Code-centric workflows looking for inline completions and an integrated chat sidebar will find GitHub Copilot or Cursor significantly lower-friction than adapting a terminal agent into their editor workflow. Vibe is best suited for developers already working in terminal-first environments, or those willing to run the CLI alongside their editor as a separate agent interface.
What is the "Teleport" feature in Vibe remote agents?
Teleport migrates an active local CLI session to a Mistral cloud sandbox, preserving the full task history, tool-call log, approval state, and in-progress context . After migration, the developer's local machine can go offline and the session continues executing in the cloud. The developer can reconnect at any time to inspect progress, respond to approval gate prompts, or retrieve results. Teleport is distinct from starting a new cloud session: it carries the accumulated state of an in-progress local session, which matters for long-running tasks where context and intermediate decisions have built up over an extended working period.
What to Watch in the Next Six Months
Mistral's release cadence — three significant updates in five months — suggests the platform is still in active architectural development. The next meaningful signals to watch: whether Medium 3.5's modified MIT license terms are published in full (this matters commercially for self-hosted deployments at scale); whether the remote agent sandbox security model is documented at a level that satisfies enterprise security review; and whether Vibe adds a VS Code extension to compete directly with Copilot and Cursor in IDE-centric workflows. The absence of a native VS Code plugin is currently the most significant friction point for teams that want Vibe's self-hosting and MCP capabilities without changing their primary editing environment.
For Copilot and Cursor, the competitive response will likely center on MCP adoption depth and async execution. Both products have model-switching flexibility that Vibe does not, and their user bases are substantially larger. The question is whether terminal-native async execution and EU data residency — currently Vibe's most differentiated capabilities — represent a large enough segment to sustain a distinct product position, or whether those features get absorbed into the broader market at lower marginal cost.
The practical recommendation remains regardless of market trajectory: evaluate against your actual task distribution. Benchmark scores establish a baseline, but cost and quality math only resolve when modeled against real output-token volumes, actual team workflows, and specific compliance constraints. If EU data residency or air-gapped self-hosting is a hard requirement, the decision is already made. If it is not, focus on where your team spends 80% of its development time — editor or terminal — and which pricing model fits your usage shape before optimizing for benchmark rankings.
Last updated: 2026-05-28. Article reviewed against Mistral's Phase 1, Phase 2, and Phase 3 release documentation, GitHub repository state as of May 2026, and published pricing at time of writing. Benchmark scores, pricing, and license terms are subject to change with future model releases.